

AI data centers in 2026 demand 100–750 MW per site. This guide covers exact power requirements, GPU rack densities, cooling strategies, and how to choose between grid, SMR, and on-site generation.
Gartner estimates global data center electricity demand will exceed 1,000 TWh by 2026—more than the entire consumption of Japan. That’s not just a scaling problem; it’s a hard infrastructure ceiling as AI demand collides with grid limits. This guide breaks down exactly how much power AI data centers require in 2026—and how to design systems that can actually scale.
Key Takeaway
AI data center power requirements in 2026 are constrained less by hardware efficiency and more by infrastructure limits. Modern AI facilities demand 100–750 MW per site, driven primarily by inference workloads and high-density GPU clusters like NVIDIA Blackwell. Winning strategies combine grid access, on-site generation, and liquid cooling — optimizing for tokens per watt, not just PUE.
What Are AI Data Center Power Requirements — And Why They Matter in 2026
AI data center power requirements refer to the total electrical capacity needed to run compute, cooling, networking, and storage systems supporting AI workloads.
The urgency in 2026 is straightforward: AI demand has structurally outpaced energy infrastructure. Gartner estimates global data center electricity demand will exceed 1,000 TWh by 2026 — double the 2023 baseline. For a full breakdown of what’s driving those numbers, see our detailed power requirements analysis. But the harder constraint isn’t generation — it’s delivery.
What changed the calculus is the shift from training to inference. Training runs are burst workloads — intense, periodic, and predictable. Inference is continuous, globally distributed, and latency-sensitive. It now accounts for 80–90% of total AI compute load across major vendors. That means data centers must sustain constant high-wattage draw, not just peak capacity.
Who this affects:
- Hyperscalers building 100 MW+ campuses in constrained grid markets
- Enterprises deploying private AI clusters on colocation or owned infrastructure — particularly those shifting from legacy search to enterprise AI knowledge platforms
- Governments investing in sovereign AI infrastructure where energy independence matters
- Colocation providers repricing power contracts in response to GPU rack density
If your organization is planning an AI deployment in the next 12–18 months, your power strategy is now a first-order infrastructure decision — not a facilities afterthought.
How Much Power Does an AI Data Center Actually Use? (2026 Numbers)
| Deployment Type | Power Range | GPU Scale | Typical Use Case |
| Edge AI cluster | 1–10 MW | Hundreds of GPUs | Regional inference, latency-sensitive apps |
| Enterprise AI facility | 10–100 MW | Thousands of GPUs | Private LLM deployment, RAG pipelines |
| Hyperscale AI campus | 100–750 MW | Tens of thousands of GPUs | Foundation model training + inference at scale |
| Sovereign AI infrastructure | 50–300 MW | Government-mandated compute | National AI programs, defense, research |
A single NVIDIA GB200 NVL72 rack draws 120–140 kW. A traditional enterprise data center built for 10–15 kW per rack cannot physically support these systems without full infrastructure redesign.
At the hyperscale end, Microsoft’s AI data center campuses now rival small cities in energy draw. A 500 MW facility running at 90% utilization consumes approximately 3.9 TWh annually — comparable to the yearly electricity use of around 360,000 US homes.
Power Solutions Compared: Grid, SMR, Gas, and Renewables
| Solution Type | Best For | Key Strength | Key Limitation | Cost Tier |
| Grid Power (Utility) | Existing facilities | Easy integration, regulated | 4–7-year connection waits in major hubs | $$ |
| Small Modular Reactors (SMRs) | Hyperscalers, long-term bets | 24/7 carbon-free baseload | High capex, regulatory complexity | $$$$ |
| Natural Gas On-Site | Transitional deployments | Fast to deploy, reliable | Carbon emissions, fuel price exposure | $$$ |
| Renewable + Battery Storage | EU-regulated markets | Low carbon, compliance-ready | Intermittency without advanced storage | $$$ |
The honest answer: No single solution fits every operator. The decision depends on your timeline, scale, regulatory environment, and risk tolerance. The sections below break each down.
The Four Power Strategies
Grid Power (Utility-Based)
Grid power remains the default for most enterprises — it’s regulated, familiar, and requires no upfront generation investment.
The problem is availability. New high-capacity grid connections in major data center hubs (Northern Virginia, Dublin, Singapore, Amsterdam) now face 4–7 year wait times. Interconnection queues in the US alone exceeded 1,500 GW as of 2025 (Lawrence Berkeley Lab). Policies like Texas SB6 give grid operators authority to curtail power during emergencies, introducing uptime risk for compute-critical workloads.
Choose grid power if: You operate an existing facility, have utility contracts already in place, and your AI workloads are sub-100 MW.
Small Modular Reactors (SMRs)
SMRs represent the most significant long-term shift in data center energy strategy. They provide continuous, on-site nuclear generation — up to 99.9% uptime — without the transmission bottlenecks that constrain grid access.
Microsoft, Google, and Amazon have all announced nuclear power agreements. The model is co-location of compute with energy production: you own (or contract) the power source, eliminating dependence on local utilities.
The constraints are real. SMR projects require 5–10-year lead times, significant regulatory navigation, and upfront capital in the hundreds of millions. For hyperscalers with 20-year infrastructure horizons, these are manageable. For enterprises on 3–5-year cycles, they are not.
Choose SMRs if: You are a hyperscaler or AI-native company with long planning horizons, face severe grid constraints, and have the capital and regulatory capacity to pursue nuclear permitting.
Natural Gas (On-Site Generation)
Natural gas turbines remain the fastest path to on-site power — deployable in 12–18 months versus years for grid upgrades or nuclear projects. They provide firm, dispatchable generation that doesn’t depend on weather or grid stability.
The tradeoffs are sustainability and cost volatility. Gas generation exposes operators to fuel price fluctuations and creates direct carbon liability — a growing risk in EU-regulated markets and under ESG reporting requirements. Many operators use natural gas as a bridge strategy while pursuing longer-term renewable or nuclear options.
Choose on-site gas if: You need power fast, face immediate grid constraints, and have a credible transition plan for decarbonization within 5–7 years.
Renewable Energy + Battery Storage
Solar and wind paired with battery storage offer the lowest carbon footprint and strongest compliance profile for EU operators subject to GDPR-adjacent digital infrastructure regulation and national energy mandates. This aligns directly with the broader EU sovereign AI infrastructure stack, where control over energy sourcing is treated as inseparable from control over compute.
The practical constraint is intermittency. Without sufficient storage, renewable-only facilities cannot guarantee the sustained low-latency power AI inference requires. The economics of battery storage at 100+ MW scale remain challenging, though costs are declining rapidly.
Choose renewables + storage if: You operate in EU markets, face regulatory pressure on sustainability reporting, and can design around variable generation with adequate storage depth.
The Blackwell Power Reality: 150 kW Per Rack Changes Everything
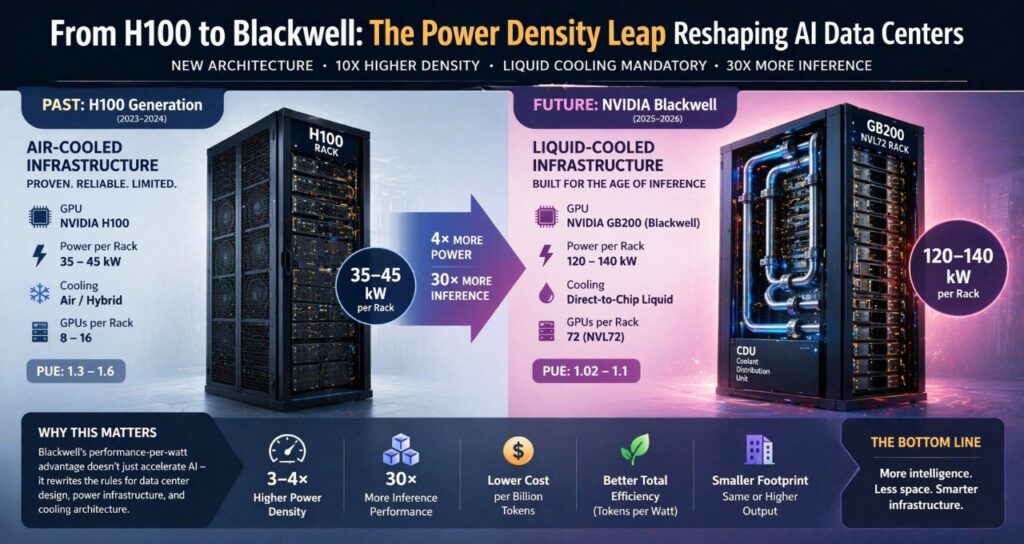
The introduction of NVIDIA’s Blackwell architecture has fundamentally changed data center design assumptions. This is not incremental — it is a structural break.
| Component | Power Draw | Cooling Requirement |
| B200 GPU | 700W – 1,000W | Advanced air or liquid |
| GB200 Superchip | 1,200W – 2,700W | Liquid cooling mandatory |
| GB200 NVL72 Rack | 120 kW – 140 kW | Full direct-to-chip liquid |
| H100 Rack (prior gen) | 35 kW – 45 kW | Air or hybrid |
Four Implications for Infrastructure Teams
1. The legacy wall is real. Most enterprise data centers were designed for 10–15 kW per rack. Blackwell requires 8–10× that density. Deploying Blackwell in a legacy facility without redesign is not feasible — it trips breakers, overwhelms cooling, and violates fire suppression ratings.
2. Liquid cooling is not optional. Air cooling cannot physically dissipate 140 kW from a single rack. Direct-to-chip liquid cooling systems are now standard for any Blackwell deployment. Rear-door heat exchangers are insufficient. Full direct liquid cooling (DLC) or immersion is required.
3. Cost reframing. A single GB200 NVL72 rack costs $2–3 million in hardware alone and consumes over 1 GWh annually at high utilization. This changes the economics of colocation versus owned infrastructure.
4. Performance-per-watt is the right metric. Blackwell delivers up to 30× inference performance improvement over H100 per vendor benchmarks. A facility running fewer Blackwell racks at high utilization may use less total energy than a larger H100 cluster while serving far more traffic. The unit of optimization is tokens per watt, not watts per rack.
For a deeper look at how these density requirements are reshaping facility design across Europe, see our guide to Blackwell infrastructure deployments across Europe.
Cooling Architecture in 2026: PUE Is the Wrong Metric
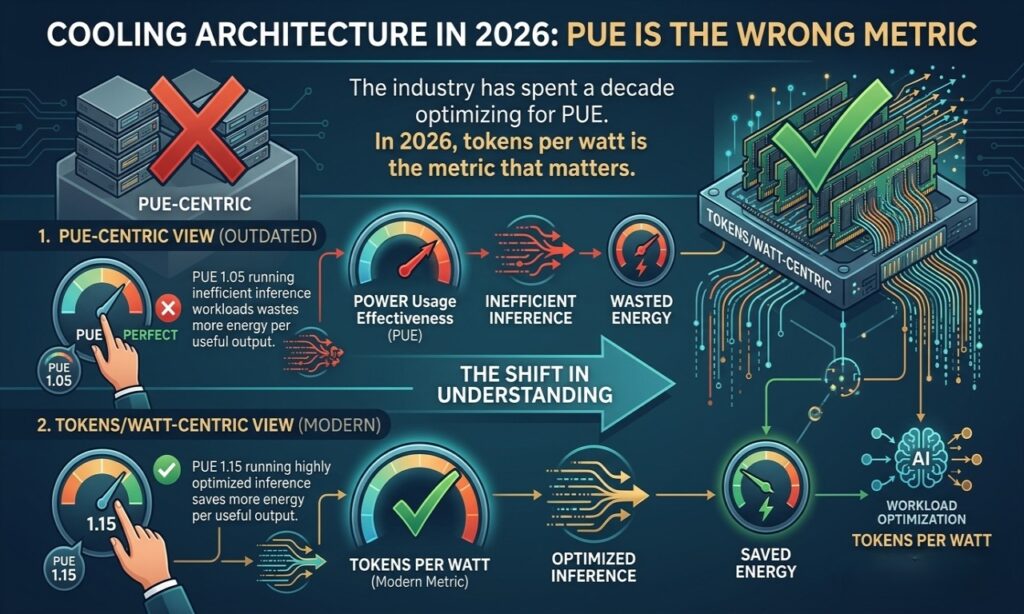
The industry has spent a decade optimizing for Power Usage Effectiveness (PUE). PUE measures overhead efficiency — how much of your total power actually reaches compute. A PUE of 1.0 is perfect; 1.5 means 50% overhead.
The problem: PUE says nothing about what your compute is doing.
A facility with PUE 1.05 running inefficient inference workloads wastes more energy per useful output than a facility with PUE 1.15 running highly optimized inference. In 2026, tokens per watt is the metric that matters — it captures both infrastructure efficiency and workload optimization.
Cooling Options by Rack Density
| Cooling Type | Max Rack Density | PUE Range | Suitable For |
| Traditional air cooling | Up to 20 kW/rack | 1.3–1.6 | Legacy systems, H100 and below |
| Rear-door heat exchangers | 20–40 kW/rack | 1.2–1.4 | Mid-density GPU clusters |
| Direct liquid cooling (DLC) | 40–150 kW/rack | 1.03–1.1 | Blackwell, high-density GPU |
| Full immersion cooling | 100–200+ kW/rack | 1.02–1.05 | Extreme density, experimental |
Microsoft’s integration of direct liquid cooling in AI facilities reduced energy overhead by up to 30% in disclosed benchmarks while significantly increasing compute density per square meter. The result is higher performance per megawatt and lower operational cost per token.
The AI Power Stack: A Layered Framework for 2026
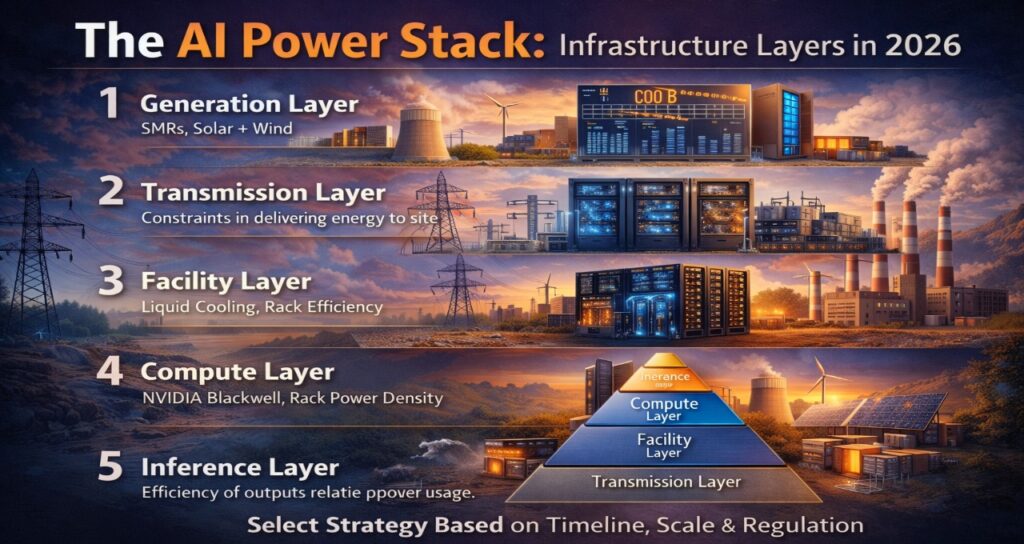
Infrastructure bottlenecks are rarely located where teams expect them. Use this layered model to identify where your constraint actually sits:
- Generation Layer — Where energy is produced. Are you on grid, on-site gas, SMR, or renewables? Is your generation capacity firm or variable?
- Transmission Layer — How power reaches your facility. Are you subject to interconnection queues? What is your transmission redundancy? Are there regulatory curtailment risks?
- Facility Layer — Cooling architecture, PUE, power distribution. Is your infrastructure rated for 100+ kW racks? Do you have liquid cooling infrastructure?
- Compute Layer — GPU generation, rack density, hardware efficiency. What is your actual utilization rate? Are you running the right hardware for your workload profile?
- Inference Layer — Workload optimization. What is your tokens-per-watt ratio? Are you batching effectively? Have you evaluated quantization or distillation to reduce per-token compute cost?
Most enterprises optimizing at Layer 3 (PUE) have no view into Layer 5, where the largest efficiency gains now sit. Start at Layer 1 to understand your access risk, then work down to Layer 5 to understand your output efficiency.
How to Choose the Right Power Strategy: Decision Framework
Choose grid power if:
- You have existing infrastructure with utility contracts
- Your AI deployments are under 100 MW
- Your timeline requires availability within 1–2 years
Choose SMRs or on-site generation if:
- You are a hyperscaler or AI-native company planning at 10+ year horizons
- You face grid access constraints in your target markets
- Long-term cost predictability outweighs upfront capital requirements
Choose renewables + battery storage if:
- You operate in EU markets with sustainability mandates
- Carbon reporting is a material regulatory or investor concern
- You can engineer around generation variability
Avoid committing to any strategy if:
- You cannot secure reliable long-term energy contracts
- Your facility is not rated for the rack densities your compute roadmap requires
- You have not mapped your inference workload efficiency (tokens per watt) as a baseline
Real-World Case Study: Microsoft’s Liquid Cooling Deployment
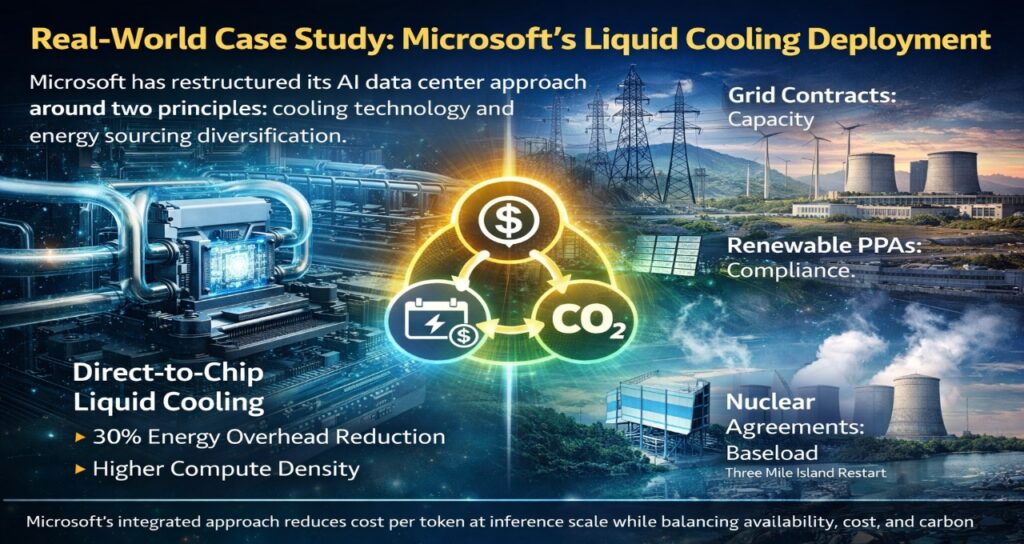
Microsoft has restructured its AI data center approach around two principles: cooling technology and energy sourcing diversification.
In deployments integrating direct-to-chip liquid cooling, the company reported energy overhead reductions of up to 30% compared to air-cooled equivalents — while simultaneously increasing compute density. This is not a theoretical efficiency gain: it directly reduces cost per token at inference scale.
On the energy side, Microsoft has moved toward a portfolio approach: existing grid contracts for near-term capacity, renewable PPAs for sustainability compliance, and nuclear agreements (including the Three Mile Island restart) for long-term baseload. The strategy reflects the reality that no single power source adequately addresses all three constraints — availability, cost, and carbon.
FAQ
1.What are AI data center power requirements in 2026?
Ans-AI data centers require anywhere from 10 MW (enterprise private clusters) to 750 MW+ (hyperscale campuses) depending on scale and workload. The dominant driver is continuous inference load, which now accounts for 80–90% of total AI compute consumption. Unlike training workloads, inference runs 24/7 at low latency — requiring firm, sustained power rather than burst capacity.
2.How much power does a single AI GPU rack use?
Ans-With NVIDIA Blackwell (GB200 NVL72), a single rack draws 120–140 kW. Previous-generation H100 racks drew 35–45 kW. This 3–4× density increase is the primary reason legacy data center infrastructure cannot support modern AI deployments without redesign.
3.Why is inference consuming more power than training?
Ans-Training is periodic — a large model may train for weeks or months, then the job is complete. Inference runs continuously at global scale to serve users in real time. The cumulative energy draw of billions of inference requests per day exceeds the energy draw of even large training runs when measured over a full year.
4.What is PUE and why is it less important than tokens per watt?
Ans-PUE (Power Usage Effectiveness) measures how efficiently a facility delivers power to compute. A PUE of 1.0 is perfect. But PUE doesn’t measure what the compute actually produces. A facility with excellent PUE running inefficient inference code still wastes energy per useful output. Tokens per watt — the number of inference tokens generated per unit of energy consumed — is a more actionable optimization target in 2026.
5.Are SMRs a realistic option for enterprise data centers?
Ans-For most enterprises, no — not within a 3–5 year planning horizon. SMR projects require 5–10 years from permitting to operation, significant capital, and dedicated regulatory expertise. They are currently a realistic option only for hyperscalers and governments with long infrastructure horizons and access to specialized nuclear development capacity.
6.How many GPUs can a 100 MW data center support?
Ans-At Blackwell density (140 kW per rack, 72 GPUs per rack), a 100 MW facility with a facility overhead of PUE ~1.1 delivers approximately 91 MW to compute — supporting roughly 650 GB200 NVL72 racks and approximately 47,000 B200 GPUs. At H100 density, the same facility supports significantly more racks but delivers substantially lower inference throughput per megawatt.
7.What cooling system does Blackwell require?
Ans-Direct liquid cooling is mandatory for GB200 NVL72 systems. Air cooling cannot dissipate 140 kW per rack. Facilities deploying Blackwell must install direct-to-chip liquid cooling infrastructure, including coolant distribution units (CDUs), leak detection, and compatible rack designs. Rear-door heat exchangers are not sufficient at this density.
Conclusion: The Energy Constraint Is Now a Compute Constraint

AI data center power requirements in 2026 are not simply an infrastructure problem — they are a strategic one. The organizations that will scale AI effectively are not those with the most GPU capacity on paper. They are the ones who secured power access years in advance, designed for liquid cooling from the ground up, and measure their efficiency in tokens per watt rather than PUE.
The next generation of AI deployments will not be constrained by model architecture or hardware availability. They will be constrained by whether your facility can physically deliver 140 kW to a rack, whether your utility can supply 500 MW without a seven-year queue, and whether your inference workloads are efficient enough to justify the energy bill.
Start with your power strategy. Build your compute roadmap around it.
Editorial Transparency & Disclosure
Methodology & Expertise This 2026 Power Infrastructure Audit was produced by the Tech Plus Trends editorial team through a multi-layered verification process.
- Data Sources: Technical specifications for the NVIDIA Blackwell (GB200 NVL72) and SMR deployment timelines were cross-referenced against official Q1 2026 data center architecture filings and energy procurement reports from the Lawrence Berkeley National Laboratory and Gartner.
- Original Frameworks: The “Tokens-per-Watt” efficiency model and the “Layered Power Stack” framework are original editorial concepts developed by Saameer to assist infrastructure leaders in moving beyond legacy PUE metrics.
AI Disclosure In accordance with our Responsible AI Journalism Policy:
- Human Authorship: The strategic analysis, “Grid-to-Chip” logic, and concluding insights are 100% authored by human experts.
- Generative Assistance: AI tools were utilized solely for large-scale data synthesis, drafting structural outlines, and rendering high-fidelity technical blueprints to assist in visualizing complex cooling and energy flow architectures.
- Fact-Checking: Every data point, from the 140 kW rack density to the 1,000 TWh global demand forecast, has been manually verified for accuracy to ensure zero hallucination.
Financial Independence Tech Plus Trends maintains strict editorial independence. We have no financial affiliation, sponsorship, or partnership with NVIDIA, Microsoft, any utility provider, or SMR manufacturer mentioned in this guide. This analysis is funded by our readers to provide objective procurement and engineering guidance.
Author bio-
Saameer is a technology journalist and infrastructure analyst covering AI systems, data center architecture, and EU digital policy. His work focuses on the gap between AI vendor claims and real-world enterprise deployment.