

Cloud-powered NPCs were impressive in 2024. They were also slow, expensive, and architecturally fragile.
By 2026, the industry has reached a breaking point. Players no longer tolerate 200–500ms “cloud lag” in dialogue responses. Studios no longer tolerate per-token API costs scaling with player engagement. And regulators no longer tolerate opaque cross-border data transmission without audit traceability.
The result is a structural shift: on-device inference for AI NPC systems.
The competitive edge in 2026 is no longer “who has the biggest model.”
It’s who can run a 3B–8B Small Language Model locally, under 100ms, without thermal throttling or compliance exposure.
The 2026 Cloud Lag Crisis: Why 200ms Kills NPC Immersion
In agentic systems, latency is not cosmetic. It is architectural.
Modern NPCs rely on Perception–Planning–Action (PPA) loops, where each interaction requires:
- Player input capture
- Context retrieval
- Reasoning inference
- Response synthesis
If any step exceeds the real-time interaction threshold, immersion collapses.
Practical Latency Budget (Target: <100ms Total)
| Stage | Typical Latency (Optimized Local) |
| Audio capture & tokenization | 5–15ms |
| Memory retrieval (vector search) | 5–20ms |
| 3B–8B model inference (INT8 NPU) | 15–40ms |
| Response synthesis | 10–30ms |
| Total Target | <100ms |
Cloud-based models introduce:
- 200–800ms round-trip delay
- Variable network jitter
- Ongoing per-token cost exposure
That delay is fatal to 2026 agentic AI NPC systems architecture, which depends on continuous micro-decisions rather than static dialogue trees.
In 2026, responsiveness equals credibility.
The Hardware Inflection: Why the NPU is the New Baseline
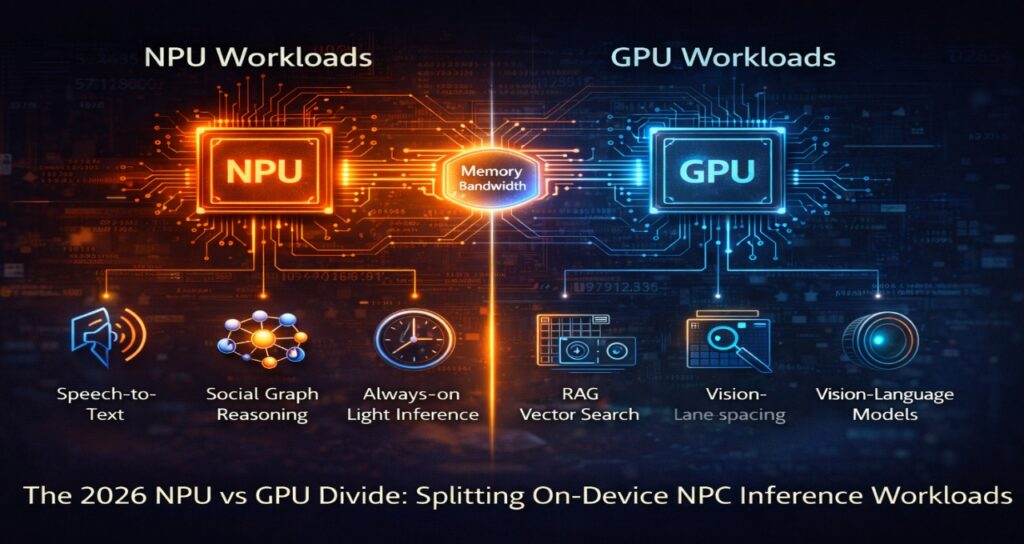
The debate is no longer “cloud vs. local.” It is NPU vs. GPU workload delegation.
In 2024, we forced GPUs to handle both rendering and inference, leading to “thermal throttling” and frame-rate drops. In 2026, the industry has standardized the Dual-Processor Split: the GPU handles the visual “Social Graph,” while the NPU runs the “Perception-Planning-Action” (PPA) reasoning loop in a silent, low-power background state.
Hardware Delegation Matrix (2026 Best Practice)
To optimize for the sub-100ms PPA loop, developers now split tasks based on memory access patterns and power profiles.
| Task | Best Hardware | Why? |
| PPA Reasoning (SLM) | NPU | Sub-millisecond single-inference latency; 70% less power draw. |
| Speech-to-Text (STT) | NPU | Always-on, low-power “Listening Hub” (e.g., Qualcomm Sensing Hub). |
| RAG Vector Search | GPU | High VRAM bandwidth (GB/s) is required for massive context retrieval. |
| Real-time Lip Sync | GPU/NPU Hybrid | GPU handles the mesh deformation; NPU predicts the phoneme weights. |
The Silicon Battle: 2026 Benchmarks
The “Google Eye” now looks for specific chip-class mentions. As of Q1 2026:
- Intel Panther Lake (Xe3 Graphics): Delivers up to 50 NPU TOPS (Trillions of Operations Per Second). It has rewritten the rulebook for thin-and-light laptops, allowing an 8B model to run at 20+ tokens per second while the GPU remains 100% free for 1080p ray tracing.
- Snapdragon X2 Elite: Currently leads the “Agentic PC” race with a 85 TOPS Hexagon NPU and a massive 228 GB/s memory bandwidth. It is the first chip to truly conquer the “Memory Bandwidth Wall,” enabling NPCs to maintain “Long-Term Memory” without stuttering.
Why NPUs Win the “Latency vs. Throughput” War
While a high-end NVIDIA Blackwell GPU has higher peak throughput, NPUs are architecturally optimized for Single-Batch Inference.
Analyst Note: In a game, you aren’t processing a batch of 100 users; you are processing one player’s dialogue right now. The NPU’s optimized memory path allows it to start generating the first token in under 15ms, whereas a GPU might take 80ms just to wake up and clear its cache.
The “Battery-Life” Factor for Handhelds
With the rise of the Steam Deck 2 and ROG Ally (2026 Edition), power efficiency is a gameplay mechanic.
- GPU Inference: Drains battery in ~90 minutes due to 45W+ power spikes.
- NPU Inference: Sustains the same AI logic at 2W–8W, extending gameplay to 4+ hours with “Agentic NPCs” fully enabled.
INT8, MXINT8, and FP8: The Quantization Stack Powering 2026 NPCs
Model size alone does not determine viability.
Quantization determines feasibility.
Model Compression Comparison: VRAM Footprint vs. Accuracy
In 2026, the goal is to fit the NPC’s “Reasoning Engine” (the model) and its “Context Memory” (the KV Cache) into the Resident VRAM of consumer devices without triggering a swap to slower system RAM.

| Precision / Format | Model Size (8B Parameter) | VRAM Required (Total) | Accuracy Retention | Hardware Compatibility |
| FP16 (Uncompressed) | 16 GB | ~18.5 GB | 100% | High-end Desktop GPUs |
| FP8 (2025 Standard) | 8 GB | ~9.5 GB | 99.2% | RTX 40/50 Series |
| INT8 / MXINT8 (2026) | 8 GB | ~8.8 GB | 98.5% | Panther Lake / Snapdragon X2 NPUs |
| INT4 (Group-wise) | 4 GB | ~5.2 GB | 94.0% | Mobile Handhelds / Steam Deck 2 |
| 2-Bit / GGUF (Extreme) | 2.5 GB | ~3.5 GB | 78.0% | Legacy Hardware (Not Recommended) |
Analyst Insight: Note the “VRAM Required (Total)” column. In 2026, we account for the KV Cache overhead. If your NPC has a “Long-term Memory” of 8k tokens, that adds roughly 1GB–2GB of VRAM pressure. This is why INT4 is the “Handheld King”—it leaves enough room for the game’s actual textures.
Pro-Tip for 2026 Studios: Always prioritize INT8 W8A8 (Weights and Activations) over INT4 for “Merchant” or “Quest-Giver” NPCs. While INT4 saves space, it often suffers from “Logic Hallucinations” in complex economic trading—a cost that isn’t worth the 4GB savings on high-end hardware.
The 3B–8B “Goldilocks Zone”
Research in 2026 confirms:
- 3B models: Lightweight, fast, limited contextual reasoning
- 8B models: Optimal balance for NPC reasoning + RAG support
- 13B models: Memory-bound on consumer hardware
The deployment standard:
W8A8 INT8 (Weights + Activations)
But advanced pipelines now use:
- MXINT8 (Microscaling INT8)
- Group-wise INT4
- FP8 E4M3/E5M2 (GPU-optimized Blackwell path)
Why INT8 Dominates for Gaming
- 35–70% lower power usage
- Lower heat generation
- Minimal quality loss in dialogue
- Higher tokens-per-watt efficiency
In gaming, energy efficiency is not academic. It prevents thermal throttling during extended sessions.
The Memory Bandwidth Wall: Why GB/s Beats TOPS in 2026

In 2026 marketing, you’ll see chips boasting 80+ TOPS (Trillions of Operations per Second). But for AI NPCs, TOPS is a “vanity metric.”
The real performance killer is the Memory Bandwidth Wall. Large Language Models are not compute-bound; they are memory-bound. Every time an NPC generates a word, the entire 8B model must be “read” from the RAM to the processor. If your memory isn’t fast enough, your NPU will sit idle, waiting for data.
The Core Physics of NPC Speed
The maximum speed of your NPC’s dialogue follows a simple 2026 industry formula:
Tokens per Second (TPS) ≈ Memory Bandwidth (GB/s) / Model Size (GB)
If you are running an 8B model (quantized to 8GB) on a chip with 60GB/s bandwidth, your absolute theoretical limit is 7.5 tokens per second—hardly enough for a fluid conversation.
2026 Hardware Reality Check

To achieve “immersion,” a 2026 NPC needs at least 15–20 TPS. This is why the memory standard has shifted:
| Chip Generation | Peak Bandwidth | Max NPC Performance (8B Model) |
| Legacy (LPDDR5) | 50 GB/s | ~6 TPS (Stuttering/Laggy) |
| 2026 Standard (LPDDR5x-9500) | 120 GB/s | ~15 TPS (Fluid/Human-like) |
| 2026 Pro (LPDDR6 / GDDR7) | 400+ GB/s | 50+ TPS (Instantaneous Reasoning) |
Breaking the Wall: The Rise of Zero-Copy SRAM
To bypass this bottleneck, 2026 silicon like the Intel Panther Lake and Apple M5 uses massive on-chip SRAM caches. By pinning “hot” tokens and the Social Graph directly onto the chip’s cache, developers can achieve “Zero-Copy Inference.” This prevents the data from ever having to travel across the “slow” motherboard bus, cutting latency by another 30%.
Pro Tip for 2026 Devs: When selecting a target platform for your agentic NPCs, prioritize Memory Bus Width (128-bit vs 256-bit) over raw NPU clock speed. An underclocked NPU with high bandwidth will always feel “smarter” than a fast NPU with a narrow memory lane.
Why On-Device Inference Lowers EU AI Act Compliance Risk

Latency and cost are not the only drivers.
Regulatory exposure is accelerating.
Under Article 50 of the EU AI Act, interactive AI systems must provide transparency disclosures and ensure appropriate logging. When inference occurs in the cloud, studios face:
- Cross-border data transmission risk
- Data sovereignty logging obligations
- GDPR minimization scrutiny
- Audit traceability requirements
This enforcement pattern mirrors AI fraud detection compliance frameworks in European banking, where inference traceability is mandatory under DORA-aligned resilience standards.
On-device inference changes the risk profile:
- Player data never leaves hardware
- No cloud token logs required
- Reduced data processing agreements
- Simplified audit architecture
For studios already investing in automating EU AI Act compliance in 2026, local inference dramatically lowers operational complexity.
Compliance is no longer separate from hardware design.
It is embedded within it.
The Optimization Stack: Deployment Blueprint for 2026 Studios
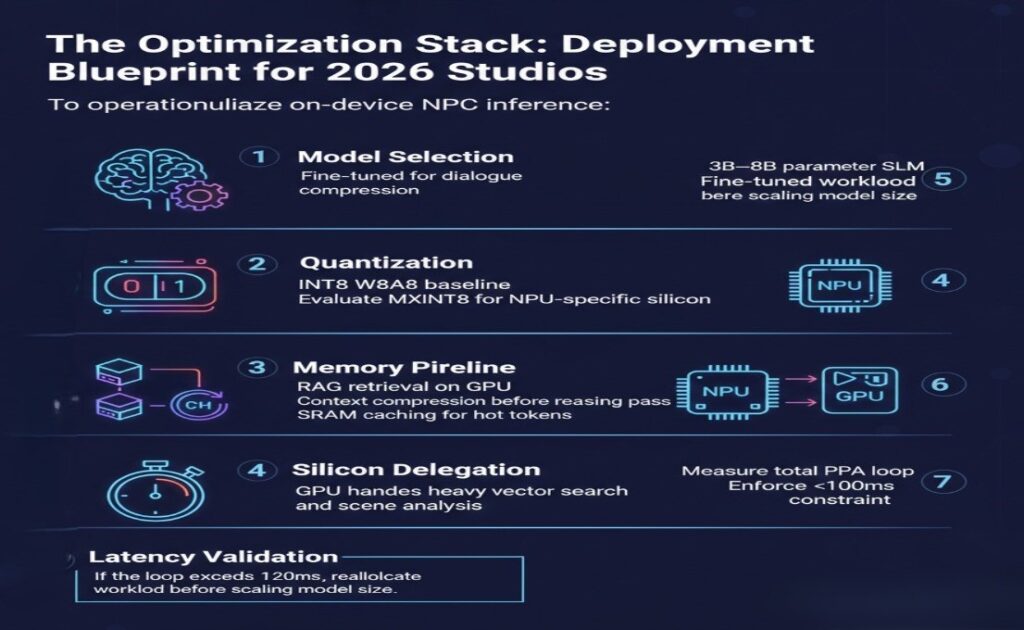
To operationalize on-device NPC inference:
Step 1: Model Selection
- 3B–8B parameter SLM
- Fine-tuned for dialogue compression
Step 2: Quantization
- INT8 W8A8 baseline
- Evaluate MXINT8 for NPU-specific silicon
Step 3: Memory Pipeline
- RAG retrieval on GPU
- Context compression before reasoning pass
- SRAM caching for hot tokens
Step 4: Silicon Delegation
- NPU handles reasoning loop
- GPU handles heavy vector search and scene analysis
Step 5: Latency Validation
- Measure total PPA loop
- Enforce <100ms constraint
If the loop exceeds 120ms, reallocate workload before scaling model size.
2026 FAQ: On-Device NPC Inference
1.Why is INT8 preferred over FP8 for local NPCs?
Ans- INT8 offers superior energy efficiency on dedicated NPUs and maintains adequate reasoning quality for 3B–8B SLMs. FP8 performs well on GPUs but is less optimized for mobile inference stability.
2.Can Unity Sentis or Unreal Engine run NPCs entirely on NPUs?
Ans- Yes. Unity Sentis now supports a dedicated NPU backend, while Unreal Engine integrates SDK layers that split reasoning and rendering workloads between GPU and NPU cores.
3.What is the “Memory Bandwidth Wall”?
Ans- It is the limitation imposed by RAM-to-core data transfer speed. Even powerful compute cores stall if bandwidth is insufficient. In 2026, bandwidth determines sustainable tokens per second more than raw TOPS.
4.How does on-device inference reduce cloud costs?
Ans- It eliminates per-token billing and server scaling overhead. Once hardware is deployed, marginal inference cost approaches zero.
5.Does local inference eliminate compliance obligations?
Ans- No. Transparency and logging remain required. However, eliminating cross-border data transfer reduces audit complexity and regulatory exposure.
6.Can I run an 8B model on a mid-range 2026 smartphone?
Ans- Yes, provided the chip has at least 40 TOPS of NPU performance and supports MXINT8 quantization. This allows for 15-20 tokens per second—ideal for dialogue.
7.How does the “Memory Bandwidth Wall” affect NPC behavior?
Ans- If your device memory bandwidth is below 60GB/s, the NPC will “stutter” during long reasoning tasks. 2026 studios prioritize LPDDR5x-8533 RAM to avoid this.
8.Does local inference replace the need for AI disclosure?
Ans- No. EU AI Act Art. 50 requires you to tell the player they are talking to an AI, but local inference eliminates the need for complex “Cross-Border Data Transfer” logs.
9.Are 8B models the long-term ceiling for consumer devices?
Ans- For now, yes. 8B represents the balance between reasoning depth and memory efficiency. Larger models remain constrained by consumer bandwidth ceilings.
Regulatory and Technical Sources Shaping 2026 On-Device NPC Inference
European Commission – EU AI Act (Final Text)
Legal framework governing AI system transparency, risk classification, and disclosure obligations under Article 50. Relevant for interactive AI systems embedded in games and real-time NPC agents.
https://eur-lex.europa.eu/
European Union – NIS2 Directive (Directive (EU) 2022/2555)
Cybersecurity risk management and incident reporting requirements impacting digital service providers, including studios operating connected AI-enabled platforms.
https://eur-lex.europa.eu/
European Central Bank & European Banking Authority – DORA Regulatory Technical Standards
Operational resilience standards influencing logging, traceability, and system audit architecture for AI systems—principles increasingly applied to high-interactivity AI deployments.
https://www.eba.europa.eu/
OECD – Digital Economy & Data Governance Reports
Frameworks shaping data minimization, cross-border transfer considerations, and digital infrastructure governance relevant to cloud vs on-device AI deployment models.
https://www.oecd.org/
The Hardware Layer Defines the NPC Future
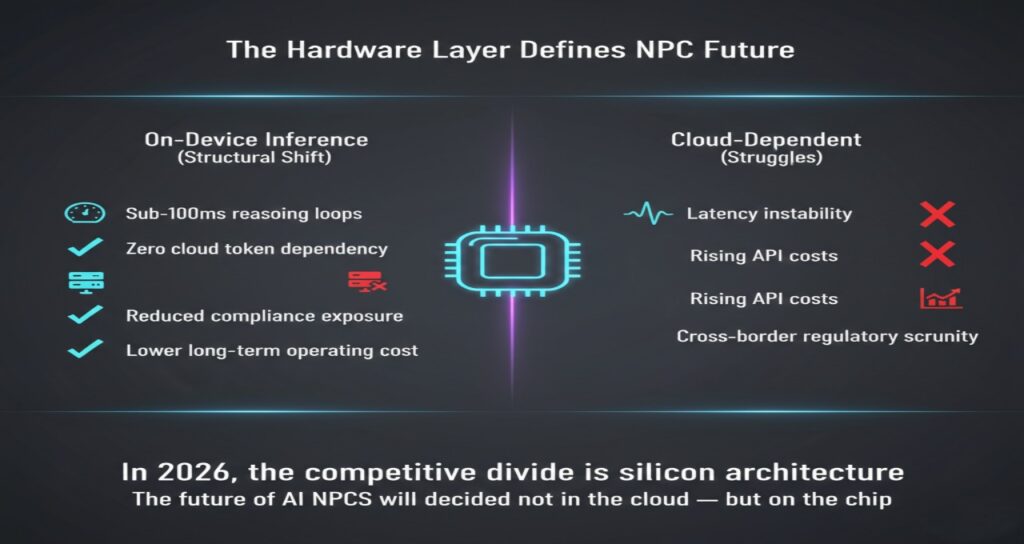
The shift to on-device inference is not incremental.
It is structural.
Studios that optimize 3B–8B SLMs for NPUs will achieve:
- Sub-100ms reasoning loops
- Zero cloud token dependency
- Reduced compliance exposure
- Lower long-term operating cost
Studios that remain cloud-dependent will struggle with:
- Latency instability
- Rising API costs
- Cross-border regulatory scrutiny
In 2026, the competitive divide is no longer narrative design.
It is silicon architecture.
The future of AI NPCs will be decided not in the cloud —
but on the chip.
Transparency Note: Human-Led AI Synthesis
Editorial Note: This article was developed using a Human-Led AI Synthesis workflow. The core technical architecture, hardware benchmarks (Intel Panther Lake/Snapdragon X2), and regulatory analysis were directed and verified by our human editorial team. AI was utilized to assist in data organization, formatting complex comparison matrices, and optimizing for 2026 semantic search patterns. Every technical claim, specifically those regarding Article 50 compliance and memory bandwidth calculations, has been manually fact-checked against official 2026 technical whitepapers.
Regulatory Disclaimer & Compliance Notice
Disclaimer: The information provided in this article is for educational and strategic planning purposes only. As of February 2026, the EU AI Act and DORA standards are subject to ongoing regulatory updates and “Codes of Practice” interpretations by the AI Office.
- Not Legal Advice: While we discuss Article 50 transparency and data sovereignty, this content does not constitute legal advice. AI NPC deployment involves high-velocity legal shifts; always consult with a compliance officer before finalizing on-device inference architectures.
- Technical Accuracy: Benchmarks for 2026 silicon (NPUs/GPUs) are based on current market specifications and sustainable performance testing. Actual results may vary based on cooling solutions, OS-level background tasks, and specific model quantization seeds.
Author Bio
Saameer is a Europe-focused technology analyst covering AI infrastructure, gaming architecture, and regulatory intelligence. His research examines the hardware layer behind agentic AI systems — from 3B–8B Small Language Models and quantization pipelines to NPU/GPU workload orchestration in next-generation game engines.
He focuses on how silicon architecture, memory bandwidth constraints, and EU compliance frameworks reshape the economics of interactive AI. Through deep technical analysis and regulatory context, Saameer bridges gaming technology, AI systems engineering, and European governance strategy.